What is serverless architecture? A Clear Guide to Modern Apps
- Expeed software
- 2 hours ago
- 17 min read
Serverless architecture is one of those cloud-computing models where the name is a bit of a lie. Servers are absolutely still involved, but the key difference is that you, the developer, no longer have to think about them. The cloud provider handles all the dynamic allocation and provisioning of servers behind the scenes.
It’s a bit like using a ride-sharing app instead of owning a car. You pay for the trip when you need it, but you're not on the hook for the car's maintenance, insurance, or finding a parking spot. You just get where you need to go.
Understanding Serverless Architecture Without The Jargon
Let's break this down with a better analogy. Imagine you're running a restaurant. The traditional way would be to own the building, the kitchen, and the dining room—these are your servers. Whether you have one customer or a hundred, you're paying for the entire space, the electricity, and the staff to keep it running 24/7. That's a lot of overhead.
Now, serverless is like running a pop-up stall at a massive food festival. You don't own the venue; you just rent a spot when you need it. You show up with your ingredients (your code), and the festival organizer provides the cooking station, power, and security (the cloud provider manages the infrastructure).
When a customer orders a dish, you cook it, serve it, and pay the organizer a small fee for that single transaction. When there are no customers, you’re not paying for anything. This is the heart of serverless: pay only for what you use, when you use it.
The Two Pillars of Serverless
This pay-as-you-go model really stands on two core components that work together, letting you build a complete application backend without the operational headaches.
Functions as a Service (FaaS): This is the brains of the operation—the compute part. You write small, self-contained pieces of code, or "functions," that do one specific thing. These functions are triggered by events, which could be anything from a user uploading a photo to an API request. The cloud provider spins up the resources to run your function, executes it, and then shuts it all down. Instantly.
Backend as a Service (BaaS): This handles all the common backend plumbing you'd otherwise have to build yourself. Instead of spinning up your own authentication system or managing a database server, you tap into managed services like AWS Cognito for user logins or Google Firebase for a real-time database. You just call their APIs and let them handle the heavy lifting.
This shift isn't just a niche trend; it's gaining serious momentum. The global serverless architecture market is on track to jump from $7.6 billion in 2020 to over $21.1 billion by 2026. This growth is fueled by companies eager to trade large capital expenses for more predictable, flexible operational costs. This new way of working lets engineering teams stop managing servers and start focusing purely on building features that actually deliver business value.
By abstracting away the underlying infrastructure, serverless architecture empowers developers to build and deploy applications faster than ever before. It shifts the focus from managing servers to writing code that solves real-world problems.
To really see why this is such a big deal, it helps to compare it directly to how things used to be done.
Serverless vs Traditional Architecture A Quick Comparison
For technical leaders, understanding the trade-offs is key. This table breaks down the fundamental differences between a traditional, server-based approach and a modern serverless model.
Aspect | Traditional Architecture (Monolith/VMs) | Serverless Architecture (FaaS) |
|---|---|---|
Server Management | You provision, manage, and scale servers. | The cloud provider manages everything for you. |
Cost Model | Pay for idle capacity (always-on servers). | Pay only for compute time used, down to the millisecond. |
Scalability | Manual or complex auto-scaling configurations. | Scales automatically and instantly with demand. |
Deployment Unit | Deploy the entire application or large service. | Deploy small, independent functions. |
Operational Overhead | High. Requires patching, updates, and maintenance. | Low. Focus is on code, not infrastructure. |
Time to Market | Slower, due to infrastructure setup and management. | Faster, as developers can ship features independently. |
The move from on-premise hardware to cloud services was the first major leap, and serverless feels like the next logical step in that evolution. If you want to dive deeper into that initial transition, understanding the differences in cloud computing vs on-premise solutions is a great place to start.
Of course, making this shift work requires a team that truly understands the new paradigm. Building that team is often the hardest part. TekRecruiter connects innovative companies with the top 1% of engineers globally who specialize in serverless technologies, so you can build a world-class team and start deploying scalable solutions right away.
Exploring The Core Components Of Serverless Systems
To really get what serverless architecture is, you have to look under the hood at its two main building blocks. These parts work together, letting your teams build powerful, scalable apps without ever touching a server config file. It’s a total shift in focus from managing infrastructure to just running code.
At its core, the serverless model splits the work, as you can see in the diagram. Your developers focus only on writing the application logic. Meanwhile, the cloud provider handles all the messy, undifferentiated heavy lifting of managing servers, databases, and message queues.
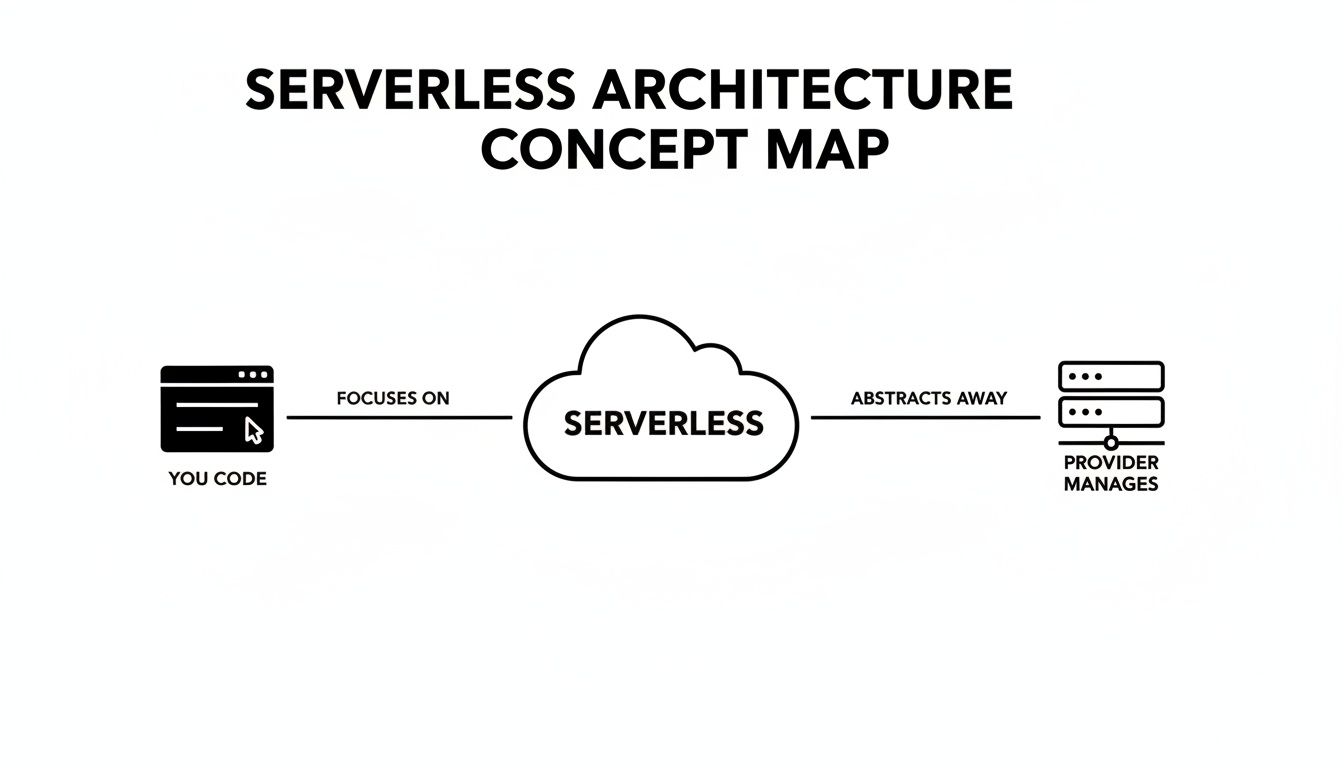
This clean separation is what unlocks the speed and efficiency serverless is known for, freeing up your engineers to build cool stuff instead of just keeping the lights on.
Functions as a Service: The Compute Engine
The first and most famous component is Functions as a Service (FaaS). Think of FaaS as the engine of your serverless system—it’s where your code actually runs. You package your logic into small, independent pieces called "functions."
These functions are stateless and built to do one specific job. They just sit there, dormant, until an event wakes them up.
An event trigger is just a signal that tells a function it's time to get to work. This can be almost anything your app needs to react to:
An HTTP request when a user clicks a button.
A new photo uploaded to a storage bucket.
A new record added to a database.
A scheduled time, like a cron job running a report at midnight.
When that trigger fires, the cloud provider instantly spins up a temporary environment, runs your function, and tears it all down the second it’s done. This "here then gone" nature is why FaaS is so cost-effective; you only pay for the exact compute time you use, often measured in milliseconds.
Backend as a Service: The Managed Toolkit
While FaaS gives you the raw compute power, you need other pieces to build a full application. That’s where Backend as a Service (BaaS) comes in. BaaS offers a suite of pre-built, fully managed backend services that your developers can plug into their apps with simple API calls.
Instead of building and maintaining your own databases or authentication systems, you just use these managed services as building blocks.
BaaS components are the essential plumbing of a serverless application. They handle common, yet critical, tasks like data storage, user authentication, and file management, allowing developers to assemble features rapidly without reinventing the wheel.
Common BaaS offerings include:
Managed Databases: Services like Amazon DynamoDB or Google Firebase give you highly scalable, fully managed NoSQL databases out of the box.
Authentication Services: Solutions like AWS Cognito or Auth0 handle user sign-up, sign-in, and access control.
Cloud Storage: Object storage like Amazon S3 provides durable, scalable storage for files, images, and other assets.
When you combine FaaS and BaaS, you create a powerful workflow. For instance, a FaaS function can be triggered when a user uploads a photo (to a BaaS storage service), which then processes the image and writes metadata to a BaaS database. Your team only wrote the image-processing code—not the complex infrastructure for file storage or database management. These components talk to each other through well-defined APIs, a critical piece of modern development. To dive deeper, check out our guide on API development best practices for modern software.
Building a team that can actually design and implement these event-driven systems is the key to making it all work. TekRecruiter specializes in connecting companies with the top 1% of serverless engineers, ensuring you have the talent to deploy robust and scalable solutions anywhere in the world.
Weighing The Strategic Benefits And Trade-Offs
Adopting any new architecture requires a clear-eyed view of what you’re gaining and what you’re giving up. For any IT director or program manager, this means looking at serverless pragmatically. You need to know where it shines and where it introduces new headaches. That’s the only way to make a strategic decision that actually drives business value.
The upsides are definitely compelling, starting with a fundamental shift in how you pay for compute. Serverless rips you out of the capital-intensive model of paying for idle servers. Instead, you move to a purely operational model where you pay only for the compute time you actually use, often measured down to the millisecond. This pay-per-execution model can lead to some pretty dramatic cost savings, especially for apps with spiky or unpredictable traffic.
Beyond the money, the operational agility is a huge win. Serverless architecture abstracts away the drudgery of managing infrastructure. Your engineers are freed from patching, provisioning, and scaling servers. This lets them focus entirely on writing code and shipping features, which directly translates to faster developer velocity and getting products to market quicker.
The Upside: A Look At Key Advantages
When you get it right, serverless delivers tangible wins that go far beyond just trimming the monthly cloud bill. It can fundamentally reshape how your teams build and deploy software.
Here's where it really pays off:
Effortless Scalability: Serverless platforms scale up—or down—automatically and instantly. Whether you have ten users or ten million, the architecture just handles it without anyone on your team needing to intervene.
Reduced Operational Overhead: By offloading server management to the cloud provider, you eliminate entire categories of operational tasks. That means less time spent on maintenance and more time dedicated to building what matters.
Faster Time-to-Market: Developers can build and deploy individual functions on their own timeline. This micro-level deployment dramatically speeds up development cycles and allows for much more rapid iteration.
The big draw for many organizations is the sheer efficiency. Enterprises have reported up to a 70% reduction in time spent managing infrastructure. That’s a massive productivity boost that lets your best engineers create value instead of just keeping the lights on.
The Downside: Navigating Potential Pitfalls
But let's be clear: serverless isn't a silver bullet. Adopting it comes with a unique set of trade-offs you need to be aware of.
One of the biggest is vendor lock-in. Serverless offerings are deeply integrated into a specific cloud provider’s ecosystem, like AWS Lambda or Azure Functions. Moving from one to the other isn't impossible, but it can be incredibly complex and expensive.
Another real challenge is the new complexity around monitoring and debugging. Traditional tools often fall short in a distributed, event-driven world. Tracing a single request as it hops between multiple functions and services requires a totally new approach to observability and a different skill set from your engineers. If you're planning a move, it's smart to review cloud migration best practices for engineering leaders to brace for these new operational demands.
And then there's the issue of cold starts. If a function hasn't been invoked recently, there can be a slight delay—latency—as the cloud provider spins up a new container to run it. While this delay is often just a few milliseconds, it can be a deal-breaker for latency-sensitive applications like real-time APIs. To really see how serverless fits in, it helps to understand the wider benefits of cloud computing for your business strategy.
The market data really highlights this trade-off. North America currently dominates the serverless market, holding 45% of the global share in 2024, largely because of the advanced cloud ecosystems from major providers. The U.S. market alone is projected for a 24% CAGR through 2030, driven by the need for scalable compute in AI and IoT. We’re seeing large enterprises use serverless to slash infrastructure costs by 30-50%, underscoring its economic power.
The table below breaks down the core pros and cons to help you weigh the decision.
Serverless Architecture Pros and Cons
Benefit | Description | Limitation | Description |
|---|---|---|---|
Cost Efficiency | Pay-per-use model eliminates costs for idle server capacity, leading to significant savings for variable workloads. | Unpredictable Costs | For high-traffic, long-running applications, the pay-per-use model can sometimes become more expensive than dedicated resources. |
Automatic Scaling | Infrastructure scales automatically and instantly to meet demand, ensuring high availability without manual intervention. | Cold Starts | Initial requests to inactive functions can experience latency (a "cold start") as resources are provisioned on demand. |
Reduced Ops Overhead | Cloud provider manages servers, patching, and maintenance, freeing up engineering teams to focus on application code. | Vendor Lock-In | Deep integration with a specific provider's services (e.g., AWS Lambda, Azure Functions) can make migration difficult and costly. |
Increased Agility | Developers can deploy small, independent functions quickly, accelerating time-to-market and enabling rapid iteration. | Debugging Complexity | Tracing issues across a distributed, event-driven system is more complex than with a traditional monolithic application. |
Ultimately, whether serverless is the right move comes down to having a team that can navigate its complexities. You need engineers with specialized expertise to truly capitalize on the benefits and mitigate the risks. TekRecruiter connects you with the top 1% of serverless and AI engineers in the world, so you can deploy a world-class team to build and scale your next great innovation.
Real-World Use Cases For Serverless Architecture
The real power of any technology isn't in its theoretical elegance but in how it performs in the wild. When you look at what serverless is actually doing for businesses, it’s clear why so many are adopting it. It's not just a buzzword; it's a practical solution for complex problems.
Serverless really shines in scenarios that are event-driven, intermittent, or have totally unpredictable workloads. So, let's move past the theory and see how real companies are using it to innovate and get a serious competitive edge.

Building Scalable APIs and Web Backends
One of the most common—and powerful—uses for serverless is powering the backend for web and mobile apps. Picture this: you launch a new mobile game, and it unexpectedly goes viral. With a traditional server setup, that sudden traffic spike would likely crash the whole system unless you had a team scrambling to provision more servers.
With a serverless model, each API request simply triggers a function. As requests surge from thousands to millions, the cloud provider automatically spins up more instances to meet demand. The app stays responsive, the users stay happy, and you only pay for the compute power you actually used during the peak. No manual intervention needed.
Take a company like Smartsheet. They optimized their architecture with serverless and saw an over 80% reduction in latency. That’s enterprise-grade performance, handled automatically.
Real-Time Data and IoT Processing
The Internet of Things (IoT) is a data firehose. You have countless devices—from smart home sensors to industrial machinery—generating massive, constant streams of information. Serverless is tailor-made for this.
Each piece of data sent from a device, like a temperature reading or a GPS coordinate, can act as an event that triggers a function. This allows for immediate data validation, transformation, and storage, all in real time.
For example, a logistics company can use serverless functions to process location data from its fleet of trucks. If a truck deviates from its route or its refrigerated cargo gets too warm, a function triggers an immediate alert. It’s an incredibly efficient way to handle sporadic, high-volume data streams.
Serverless architecture excels at processing unpredictable, bursty traffic. Companies like WellRight have modernized their systems to an event-driven model to manage these workloads, optimizing both cost and performance by reacting to events as they happen rather than paying for idle capacity.
Automating IT and DevOps Workflows
Serverless isn't just for customer-facing applications. It’s also a total game-changer for internal IT automation and CI/CD pipelines. All those repetitive tasks that used to run on a dedicated cron server are perfect candidates for a serverless function.
Think about the automation possibilities:
Scheduled Tasks: Run a function every night to scan for security vulnerabilities, clean up old log files, or generate daily performance reports.
CI/CD Automation: Trigger a function whenever new code is pushed to a repository to automatically run tests, build artifacts, and deploy to a staging environment.
Infrastructure Management: Use functions to automatically tag new cloud resources for cost tracking or shut down non-production instances over the weekend to save money.
These small, automated tasks add up. They free up your engineering team from manual toil and drastically reduce the risk of human error. The ability to execute code in response to infrastructure events makes serverless a core part of modern DevOps.
Of course, successfully implementing these use cases requires specialized talent. Finding engineers who can design, build, and secure these distributed systems is critical. TekRecruiter connects you with the top 1% of serverless and AI engineers from around the globe, allowing you to build an elite team and deploy innovative solutions anywhere.
Best Practices For Serverless Implementation
Jumping into serverless isn't just about writing functions and pushing them to the cloud. If you want to build something that lasts, you need a disciplined game plan that anticipates the unique quirks of this event-driven world. Following a solid set of best practices is what separates applications that are resilient, secure, and cost-effective from those that become a chaotic mess. Think of this as an actionable playbook for DevOps leaders and senior engineers ready to build durable serverless systems.

The journey starts by getting the function itself right. Two principles are king here: functions should be stateless and idempotent. Stateless means the function never holds onto data from a previous run. Every single execution is a clean slate, which is the secret sauce behind true scalability and reliability.
Idempotency is the other side of that coin. It simply means that calling the same function multiple times with the exact same input will always produce the same result. This is a lifesaver in distributed systems where network hiccups might accidentally trigger a function more than once. Getting idempotency right prevents duplicate data and other nasty, unintended side effects.
Mastering Observability In Distributed Systems
In a classic monolith, tracking down a bug is usually a straight line. But in the serverless world? A single click from a user could set off a chain reaction involving dozens of independent functions and services. Without the right setup, debugging feels less like engineering and more like searching for a needle in a haystack.
This is where observability becomes completely non-negotiable. It's so much more than just logging; it's about gaining a deep, intuitive understanding of your entire system's behavior. A strong observability strategy is built on three pillars:
Structured Logging: Forget plain text. Use a machine-readable format like JSON for your logs. It makes them instantly searchable and perfect for automated analysis.
Distributed Tracing: You need tools that can follow a single request as it weaves its way through your web of functions and services. This gives you a complete "trace" of the request's journey, making it dead simple to pinpoint bottlenecks or failures.
Comprehensive Metrics: Track the vital signs of your functions—execution time, memory use, error rates, and cold start frequency. This data helps you spot performance issues before they become real problems.
A serverless system without mature observability is a "black box." When things go wrong, you're flying blind. Investing in the right tools and building these practices from day one is the only way to maintain a healthy production environment.
Prioritizing Security With Least Privilege
The distributed nature of serverless naturally expands your application's attack surface. Every single function is a potential door for an attacker, which means security can't just be a wall around the perimeter—it has to be built into the function itself.
The single most important security practice is the Principle of Least Privilege. In plain English, this means each function should only have the absolute minimum permissions it needs to do its job, and nothing more. If a function only needs to read from a specific database table, its IAM role should never have write or delete permissions. This granular control dramatically shrinks the blast radius if one function ever gets compromised.
Pulling this off requires a solid grasp of cloud-native tools, which often goes hand-in-hand with Infrastructure as Code (IaC). To dive deeper into this, you can check out some of the top Infrastructure as Code best practices.
Optimizing For Cost And Performance
Finally, while serverless can be incredibly cost-effective, it isn't automatically cheap. Your bill is directly tied to two things: the memory you allocate to a function and how long it runs. "Right-sizing" your functions is everything. Give them too much memory, and you're just burning money. Give them too little, and you'll kill performance or hit timeouts.
You can use automated tools to analyze your functions and dial in the perfect memory configuration that balances cost and speed. It's also smart to keep your code and its dependencies as lean as possible. This cuts down on initialization time, which softens the blow from cold starts and lowers your overall execution costs.
Navigating these best practices demands real expertise. You need engineers who get the nuances of distributed systems, cloud security, and performance tuning. TekRecruiter bridges that talent gap, connecting innovative companies with the top 1% of serverless and AI engineers from anywhere in the world. Partner with us to build an elite team that can turn your architectural vision into a secure, scalable reality.
Build Your Elite Serverless Team With TekRecruiter
Going serverless is a huge move toward building faster and innovating more, but its success boils down to one thing: the people building it. The real challenge isn’t the tech itself. It’s finding the specialized engineers who can actually master this new way of thinking. Designing, securing, and optimizing event-driven systems requires a completely different skillset than traditional infrastructure management.
This is exactly where TekRecruiter comes in. We specialize in one thing: connecting companies like yours with the top 1% of globally-distributed engineers who live and breathe serverless ecosystems across AWS, Azure, and Google Cloud.
Why Specialized Talent Isn't Optional
To get serverless right, you need people who understand its unique patterns and its hidden traps. Without that deep expertise, companies often run into security holes, runaway costs, and nagging performance issues like cold starts. You need engineers who think in functions, events, and managed services—not just servers and VMs.
The move to serverless isn't just a technical swap; it's a cultural one. It demands a team that can build for resilience in a distributed world, master new observability tools, and lock down security at the function level.
Finding The Right Fit For Your Project
We get that every project is different. A one-size-fits-all approach to team building just doesn't cut it, which is why TekRecruiter offers flexible ways to get the talent you need.
We have a few models to help you build out a world-class team:
Staff Augmentation: Seamlessly add elite serverless engineers to your current team. It’s the fastest way to hit deadlines and fill critical skill gaps without the long hiring process.
Direct Hire: Need a permanent addition? Let us find you the perfect full-time engineer with the proven skills and cultural fit to drive your success for the long haul.
AI Engineering Solutions: For projects sitting at the intersection of serverless and AI, we can provide entire end-to-end teams ready to design, build, and deploy intelligent, scalable systems from the ground up.
Building a team that can truly master serverless is a complex game. For a deeper dive into sourcing this kind of high-level talent, check out our practical guide to hiring DevOps engineers.
The real promise of serverless—insane scalability, less operational headache, and faster innovation—is right there for the taking. Partner with TekRecruiter to build the elite engineering team you need to make it happen, no matter where they are in the world.
Got Questions About Serverless?
As leaders and engineers start digging into serverless, a few key questions always pop up. Let's cut through the noise and get straight to the practical answers you're looking for.
Is Serverless Always Cheaper Than Traditional Servers?
Not always. The real answer depends entirely on your application's traffic patterns. Serverless is an absolute money-saver for workloads with choppy, unpredictable traffic because you're only billed for the milliseconds your code is actually running.
But if you're running an application with constant, high-volume traffic, a dedicated, provisioned server might actually be more predictable and even cheaper. The big win with serverless is that you completely eliminate the cost of idle resources. This makes it a perfect match for event-driven tasks or apps that see huge, intermittent spikes in usage.
Forget paying for server capacity you might need. The real financial advantage of serverless is paying only for the exact resources you consume, right when you consume them.
How Do You Handle State In A Serverless Application?
You can't. At least, not inside the function itself. Serverless functions are intentionally built to be stateless and short-lived. Any data you store in a function's memory simply vanishes the second the execution ends.
The solution is to push your state outside the function to a separate, durable storage service. A few common—and effective—ways to do this include:
Managed Databases: Use a service like Amazon DynamoDB or Google Firestore to keep your application data safe and sound.
Caching Services: For session data or other temporary state, an in-memory store like Redis is your best friend.
Object Storage: When you need to store files or bigger chunks of data, a service like Amazon S3 is the go-to.
This approach keeps your application scalable and tough. Any function instance can grab the state it needs from that shared, external data store without missing a beat.
What Is The Biggest Security Challenge With Serverless?
The game changes completely. Instead of hardening servers, your primary security focus shifts to locking down individual functions and their permissions. Every single function becomes a potential doorway into your system, which dramatically expands your attack surface.
The single greatest risk? Handing out overly generous identity and access management (IAM) roles. You have to be ruthless about following the Principle of Least Privilege. Give each function only the exact permissions it needs to do its job, and absolutely nothing more. On top of that, you have to stay vigilant about managing third-party code dependencies and securing the data sources that trigger your functions. These are non-negotiable in any serverless environment.
Ready to build an engineering team that can master these challenges and unlock the full potential of serverless? As a leading technology staffing, recruiting, and AI Engineer firm, TekRecruiter empowers innovative companies to deploy the top 1% of engineers anywhere in the world. Build your elite team with us today.